Looker will then build a full version of the table that can be used for production when you deploy your changes. Though both are used to exclude rows from the result set, you should use the WHERE clause to filter rows before grouping and use the HAVING clause to filter rows after grouping. In other words, WHERE can be used to filter on table columns while HAVING can be used to filter on aggregate functions like count, sum, avg, min, and max. The presence of HAVING turns a query into a grouped query even if there is no GROUP BY clause. This is the same as what happens when the query contains aggregate functions but no GROUP BY clause.

All the selected rows are considered to form a single group, and the SELECT list and HAVING clause can only reference table columns from within aggregate functions. Such a query will emit a single row if the HAVING condition is true, zero rows if it is not true. When the optional WITH ORDINALITY clause is added to the function call, a new column is appended after all the function's output columns with numbering for each row. Expression_n Expressions that are not encapsulated within an aggregate function and must be included in the GROUP BY Clause at the end of the SQL statement. Aggregate_function This is an aggregate function such as the SUM, COUNT, MIN, MAX, or AVG functions.

Aggregate_expression This is the column or expression that the aggregate_function will be used on. There must be at least one table listed in the FROM clause. These are conditions that must be met for the records to be selected.
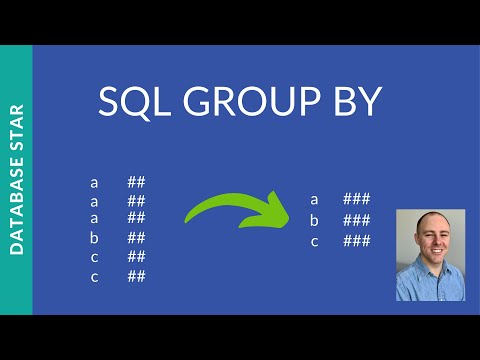
If more than one expression is provided, the values should be comma separated. DESC sorts the result set in descending order by expression. If a query contains table columns only inside aggregate functions, the GROUP BY clause can be omitted, and aggregation by an empty set of keys is assumed. All database users know about regular aggregate functions which operate on an entire table and are used with a GROUP BY clause. These operate on a set of rows and return a single aggregated value for each row. The Group by clause is often used to arrange identical duplicate data into groups with a select statement to group the result-set by one or more columns.

This clause works with the select specific list of items, and we can use HAVING, and ORDER BY clauses. Group by clause always works with an aggregate function like MAX, MIN, SUM, AVG, COUNT. All the expressions in the SELECT, HAVING, and ORDER BY clauses must be calculated based on key expressions or on aggregate functions over non-key expressions . In other words, each column selected from the table must be used either in a key expression or inside an aggregate function, but not both. For SQL-based derived tables, avoid using common table expressions . Using CTEs with DTs creates nested WITH statements that can cause PDTs to fail without warning.

Instead, use the SQL for your CTE to create a secondary DT and reference that DT from your first DT using the $ syntax. A functional dependency exists if the grouped columns are the primary key of the table containing the ungrouped column. Aggregate functions, if any are used, are computed across all rows making up each group, producing a separate value for each group. When a FILTER clause is present, only those rows matching it are included in the input to that aggregate function.

SQL aggregation is the task of collecting a set of values to return a single value. It is done with the help of aggregate functions, such as SUM, COUNT, and AVG. For example, in a database of products, you might want to calculate the average price of the whole inventory. MySQL can use this technique on complex WHERE clauses, so you may see nested operations in the Extra column for some queries. This often works very well, but sometimes the algorithm's buffering, sorting, and merging operations use lots of CPU and memory resources. This is especially true if not all of the indexes are very selective, so the parallel scans return lots of rows to the merge operation.

Recall that the optimizer doesn't account for this cost—it optimizes just the number of random page reads. This can make it "underprice" the query, which might in fact run more slowly than a plain table scan. The intensive memory and CPU usage also tends to impact concurrent queries, but you won't see this effect when you run the query in isolation. To support any type of persistent derived tables (either LookML-based or SQL-based), the dialect must support writes to the database, among other requirements.
There are some read-only database configurations that don't allow persistence to work (most commonly Postgres hot-swap replica databases). In these cases, you can use temporary derived tables instead. Otherwise, if Looker can't use cached results, Looker must run a new query on your database every time a user requests data from a temporary derived table. Because of this, you should be sure that your temporary derived tables are performant and won't put excessive strain on your database. In cases where the query will take some time to run, a persistent derived table is often a better option. Native derived tables are based on queries that you define using LookML terms.

To create a native derived table, you use the explore_source parameter inside the derived_table parameter of a view parameter. You create the columns of your native derived table by referring to the LookML dimensions or measures in your model. See the native derived table view file in the example above.

The UNION operator computes the set union of the rows returned by the involved SELECT statements. A row is in the set union of two result sets if it appears in at least one of the result sets. The two SELECT statements that represent the direct operands of the UNION must produce the same number of columns, and corresponding columns must be of compatible data types. In general, UNBOUNDED PRECEDING means that the frame starts with the first row of the partition, and similarly UNBOUNDED FOLLOWING means that the frame ends with the last row of the partition .

The value PRECEDING and value FOLLOWING cases are currently only allowed in ROWS mode. They indicate that the frame starts or ends with the row that many rows before or after the current row. Value must be an integer expression not containing any variables, aggregate functions, or window functions. The value must not be null or negative; but it can be zero, which selects the current row itself. The SQL standard requires that HAVING must reference only columns in the GROUP BYclause or columns used in aggregate functions.

However, MySQL supports an extension to this behavior, and permits HAVING to refer to columns in the SELECT list and columns in outer subqueries as well. The GROUP BY clause is a SQL command that is used to group rows that have the same values. Optionally it is used in conjunction with aggregate functions to produce summary reports from the database. If the WITH TOTALS modifier is specified, another row will be calculated.

This row will have key columns containing default values , and columns of aggregate functions with the values calculated across all the rows (the "total" values). An outer join will combine rows from different tables even if the join condition is not met. Every row in the left table is returned in the result set, and if the join condition is not met, then NULL values are used to fill in the columns from the right table. MySQL executes every kind of query in essentially the same way.

One common mistake is assuming that MySQL provides results on demand, rather than calculating and returning the full result set. We often see this in applications designed by people familiar with other database systems. They think MySQL will provide them with these 10 rows and stop executing the query, but what MySQL really does is generate the complete result set. The client library then fetches all the data and discards most of it. With aggregate analytic functions, the OVER clause is appended to the aggregate function call; the function call syntax remains otherwise unchanged. Like their aggregate function counterparts, these analytic functions perform aggregations, but specifically over the relevant window frame for each row.

The result data types of these analytic functions are the same as their aggregate function counterparts. See the Supported database dialects for PDTs section below for the lists of dialects that support persistent SQL-based derived tables and persistent native derived tables. If the combination has been run before and the results are still valid in the cache, Looker uses the cached results. See the Caching queries and rebuilding PDTs with datagroups documentation page for more information on query caching in Looker. In addition to the distinction between native derived tables and SQL-based derived tables, there is also a distinction between a temporary derived table and a persistent derived table .

When querying multiple tables, use aliases, and employ those aliases in your select statement, so the database doesn't need to parse which column belongs to which table. Note that if you have columns with the same name across multiple tables, you will need to explicitly reference them with either the table name or alias. STRAIGHT_JOIN does not apply to any table that the optimizer treats as a const or system table. These tables appear first in the query plan displayed by EXPLAIN. Rows retain their identity and also show an aggregated value for each row. In the example below the query does the same thing, namely it aggregates the data for each city and shows the sum of total order amount for each of them.

However, the query now inserts another column for the total order amount so that each row retains its identity. The column marked grand_total is the new column in the example below. The examples we've gone through up to this point include some of the more frequently-used keywords and clauses in SQL queries.

These are useful for basic queries, but they aren't helpful if you're trying to perform a calculation or derive a scalar value based on your data. An index, as you would expect, is a data structure that the database uses to find records within a table more quickly. Indexes are built on one or more columns of a table; each index maintains a list of values within that field that are sorted in ascending or descending order.
What Is The Significance Of Group By Clause In An Sql Query Explain With The Help Of Example Rather than sorting records on the field or fields during query execution, the system can simply access the rows in order of the index. In the Group BY clause, the SELECT statement can use constants, aggregate functions, expressions, and column names. Make sure that all sql_trigger_value queries evaluate successfully, and return only one row and column. For SQL-based PDTs, you can do this by running them in SQL Runner. (Applying a LIMIT protects from runaway queries.) For more information on using SQL Runner to debug derived tables, see this Community topic. When you define a SQL-based derived table, make sure to give each column a clean alias by using AS.

This is because you will need to reference the column names of your result set in your dimensions, such as $.first_order. This is why in our example above we used MIN(DATE) AS first_order instead of simply MIN(DATE). Compared to SQL-based derived tables, native derived tables are much easier to read and understand as you model your data. This left-hand row is extended to the full width of the joined table by inserting null values for the right-hand columns.

Note that only the JOIN clause's own condition is considered while deciding which rows have matches. SQL_BIG_RESULT or SQL_SMALL_RESULT can be used with GROUP BY or DISTINCT to tell the optimizer that the result set has many rows or is small, respectively. For SQL_BIG_RESULT, MySQL directly uses disk-based temporary tables if they are created, and prefers sorting to using a temporary table with a key on the GROUP BY elements. For SQL_SMALL_RESULT, MySQL uses in-memory temporary tables to store the resulting table instead of using sorting.

The GROUP BY clause is used in a SELECT statement to group rows into a set of summary rows by values of columns or expressions. A GROUP BY statement in SQL specifies that a SQL SELECT statement partitions result rows into groups, based on their values in one or several columns. Typically, grouping is used to apply some sort of aggregate function for each group.

The Group By statement is used to group together any rows of a column with the same value stored in them, based on a function specified in the statement. Generally, these functions are one of the aggregate functions such as MAX() and SUM(). JOINS are SQL statements used to combine rows from two or more tables, based on a related column between those tables. We can use the SQL GROUP BY statement to group the result set based on a column/ columns. Here, you can add the aggregate functions before the column names, and also a HAVING clause at the end of the statement to mention a condition.

This statement is used to group records having the same values. The GROUP BY statement is often used with the aggregate functions to group the results by one or more columns. We usually want to compute some statistics for this group of rows, like the average value or the total quantity. To this end, SQL provides aggregate functions that combine values from a certain column into one value for the respective group. The SELECT statement used in the GROUP BY clause can only be used contain column names, aggregate functions, constants and expressions. "Order by 2" is only valid when there are at least two columns being used in select statement.

Most such queries we see are accidents (because the server doesn't complain), or are the result of laziness rather than being designed that way for optimization purposes. In fact, we suggest that you set the server's SQL_MODE configuration variable to include ONLY_FULL_GROUP_BY so it produces an error instead of letting you write a bad query. MySQL executes this query in two steps, which correspond to the two rows in the output. The first step is to find the desired row in the film table. Because the query optimizer has a known quantity to use in the lookup, this table's ref type is const.

In this lesson you learned to use the SQL GROUP BY and aggregate functions to increase the power expressivity of the SQL SELECT statement. You know about the collapse issue, and understand you cannot reference individual records once the GROUP BY clause is used. In the case of cascading temporary derived tables, if a user's query results aren't in the cache, Looker will build all the derived tables that are needed for the query. If you have a TABLE_D whose definition contains a reference to TABLE_C, then TABLE_D is dependent on TABLE_C. This means that if you query TABLE_D and the query is not in Looker's cache, Looker will rebuild TABLE_D.

Other than the derived_table parameter and its subparameters, this customer_order_summary view works just like any other view file. Whether you define the derived table's query with LookML or with SQL, you can create LookML measures and dimensions based on the columns of the derived table. Using the GROUP BY Clause with the SELECT statement, we can group rows with the same values and aggregate functions, constants, and expressions. I discovered that it is possible to use the results of one query as the data range for a second query . So, I'm trying to use Data Validation for user selection to compare certain cells to one another .

I'm new to a lot of what sheets has to offer and not too knowledgeable, but I can normally fumble my way through it to figure it out. However, I'm trying to get query to output a single cell instead of a row or column from the data set range. If specific tables are named in a locking clause, then only rows coming from those tables are locked; any other tables used in the SELECT are simply read as usual. A locking clause without a table list affects all tables used in the statement.

If a locking clause is applied to a view or sub-query, it affects all tables used in the view or sub-query. However, these clauses do not apply to WITH queries referenced by the primary query. If you want row locking to occur within a WITH query, specify a locking clause within the WITH query.



No comments:
Post a Comment
Note: Only a member of this blog may post a comment.